
The Inevitable Chaos: Embracing Failure for Resilient Distributed Systems
Building Systems That Thrive on Failure

Engineers, by their very nature, are optimists. They are trained to build, to solve, to perfect. From the first bridge to the latest microchip, the implicit goal has always been to eliminate failure. In civil engineering, this makes sense: a bridge that fails is a catastrophe, a lesson etched in concrete and lives lost. The discipline evolves by making structures stronger, margins wider, tolerances tighter. Perfection, or at least its relentless pursuit, is a necessary creed.
But what if this very optimism, this drive for flawlessness, becomes a critical vulnerability? In the interconnected world of distributed systems, this is precisely the case. Here, perfection is not merely elusive; it's a dangerous fantasy. These systems are not monolithic structures of steel and stone. They are intricate webs built from fallible networks, unreliable processes, and constantly shifting, unpredictable dependencies. In this environment, failure isn't an anomaly to be stamped out. To pretend otherwise isn't just naive; it's a direct path to fragility.
The foundational assumptions that once underpinned system design – "the network is reliable," "latency is zero," "bandwidth is infinite," "topology doesn't change," "machines never fail" – have, by now, been disproven so often they've become industry punchlines. Yet, a ghost of this optimistic worldview lingers, leading engineers to design as if these fictions were facts. The result? Brittle systems, meticulously crafted but destined to shatter. The fundamental question we must confront is no longer "How do we prevent failure?" but rather how do we live with it.
David D. Woods, a luminary in resilience engineering, provides a crucial framework, articulating resilience through four distinct qualities: robustness, rebound, graceful extensibility, and sustained adaptability. Traditional engineering, fixated on preventing failure, has historically obsessed over robustness – the ability to withstand shocks. But distributed systems, by their very nature, demand an equal, if not greater, emphasis on the other three. Resilience isn't just about enduring; it's about the rapid recovery (rebound), the capacity to stretch and adapt under unanticipated stress without snapping (graceful extensibility), and the continuous evolution in response to new surprises (sustained adaptability).
This profound shift in mindset is the crucible from which powerful techniques like Chaos Monkey emerge. Netflix's infamous chaos engineering tool, which deliberately terminates production servers, appears, on the surface, to be an act of corporate self-sabotage. But this perspective only holds if you cling to the illusion of perpetual uptime. Once you accept the undeniable truth – that those servers will die eventually, whether by your hand or by fate – the logic becomes clear. The only remaining question is whether you will be ready. Chaos engineering isn't a juvenile exercise in breaking things for the sake of it; it's a training regimen for both systems and the human teams that manage them, preparing them to expect, confront, and overcome the unexpected.
How Systems Learn to Live With Failure: A Technical Breakdown
To truly "live with failure," we must re-architect our systems with a pessimistic, fault-tolerant mindset. This involves weaving specific patterns and practices into the very fabric of our distributed designs, transforming potential points of collapse into mechanisms of resilience.
Fault Tolerance Basics: Understanding the Enemy
Before we can build resilient systems, we must precisely define what we are resisting. It's crucial to distinguish between faults and failures. A fault is an imperfection or defect within a system (e.g., a network cable gets unplugged, a server runs out of memory). A failure is the observable manifestation of that fault, where the system deviates from its expected behavior (e.g., a service becomes unavailable, data is corrupted). Our goal isn't necessarily to eliminate every fault – an impossible task in a large distributed system – but to design fault-tolerance mechanisms that prevent faults from escalating into full-blown failures.
Consider the five classic classes of failures in Remote Procedure Call (RPC) systems, which are foundational to distributed communication:
Client unable to locate server: the service discovery mechanism fails, or the server simply isn't there.
Lost messages: network congestion, hardware errors, or routing issues prevent request or response packets from reaching their destination.
Server crashes: the process or machine hosting the service unexpectedly terminates.
Lost replies: the server processes the request but its response is lost on the way back to the client.
Client crashes: The client itself fails before it can process the server's response or retry.
Each of these scenarios, seemingly simple, can cascade into wider system collapse without careful design.
Stability Patterns
Building resilience requires a deliberate application of battle-tested patterns:
Time-outs: in a distributed system, a slow service can often be worse than a completely broken one. A service that hangs indefinitely consumes valuable resources (threads, memory, network connections) on the calling client, potentially leading to resource exhaustion and cascading failures. Timeouts ensure that clients don't wait forever, freeing up resources and allowing them to fail fast. They draw a line in the sand: if a response isn't received within X milliseconds, assume failure and move on. This prevents a single, ailing dependency from dragging down an entire application.
Retries and Exponential Backoff: when a transient fault occurs (e.g., a momentary network glitch, a database deadlock), simply trying the operation again often succeeds. However, naive retries can be disastrous. Rapid-fire retries for an overloaded or failing service can create a "thundering herd" problem, exacerbating the load and preventing recovery. This is where exponential backoff becomes critical: gradually increasing the delay between retry attempts. This gives the struggling service time to recover and prevents the retrying clients from overwhelming it further. Crucially, operations designed for retries must be idempotent – meaning performing them multiple times has the same effect as performing them once. Sending the same email twice is not idempotent; re-saving a user's profile might be.
Circuit Breakers: imagine a fuse box in your home. When a fault occurs, the circuit breaker "trips," cutting off power to prevent further damage. Circuit breakers in software operate on a similar principle. They monitor calls to a dependency. If a certain number or percentage of calls fail within a configured timeframe, the circuit "trips" open. For a period, all subsequent calls to that dependency are immediately rejected without even attempting to reach the downstream service. This prevents further load on an already struggling service, allowing it to recover, and protects the calling service from wasting resources on doomed requests. After a set "half-open" period, the circuit allows a small number of test requests through. If these succeed, the circuit closes; if they fail, it re-opens.
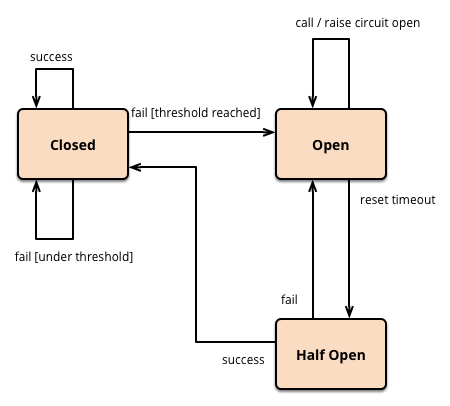
src. https://martinfowler.com/bliki/CircuitBreaker.html Bulkheads: inspired by ship construction, where watertight compartments prevent a breach in one section from sinking the entire vessel. In software, bulkheads isolate failures by partitioning resources. For example, using separate connection pools for different downstream services ensures that a flood of requests or a hung connection to one service doesn't exhaust the pool and starve other, healthy services. This can also apply to thread pools, queues, or even separate instances of a microservice, ensuring that the failure of one component doesn't bring down the entire application.
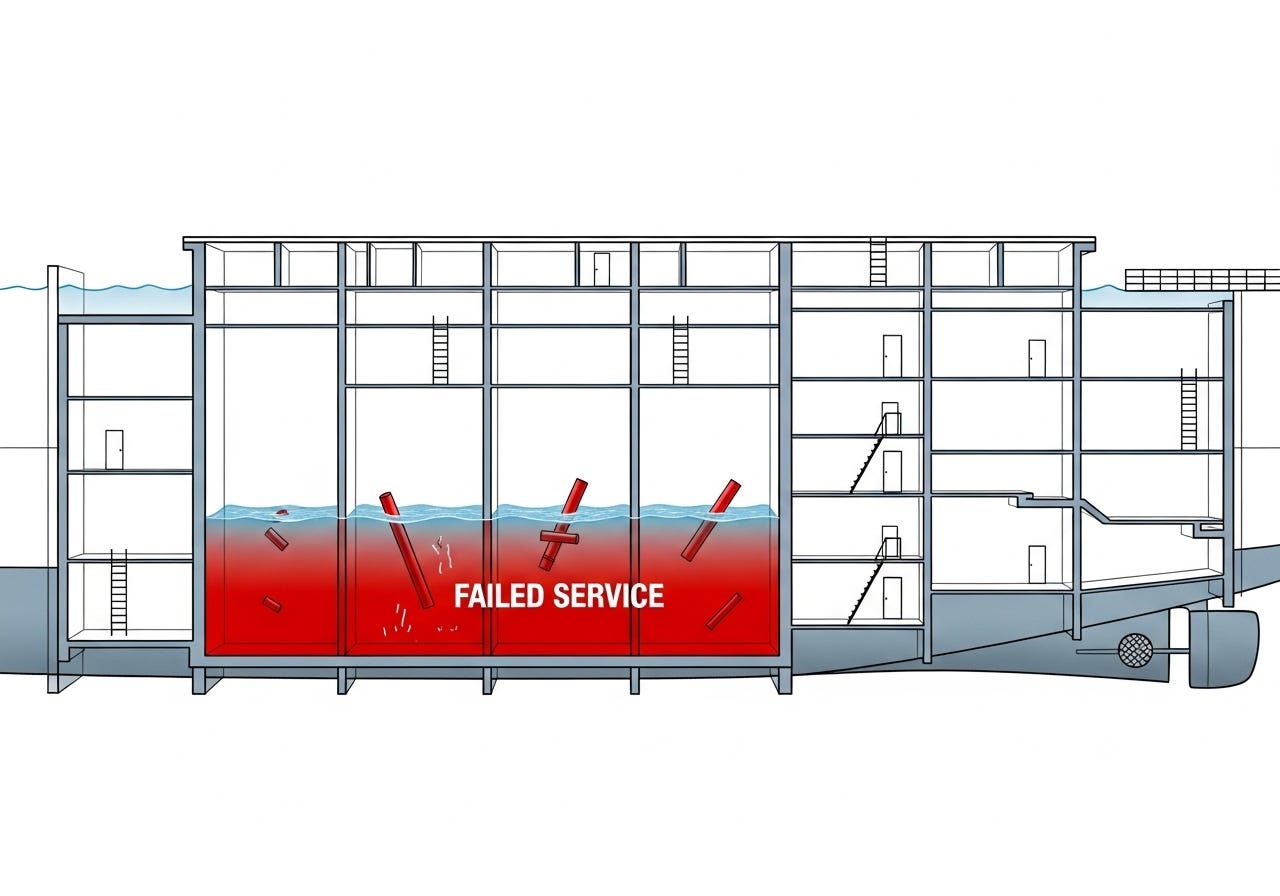
src. AI generated Load Shedding: there comes a point when a system is simply overwhelmed. Rather than struggling to process every request poorly, or crashing outright, load shedding (also known as rate limiting or throttling) allows a system to gracefully reject requests. This might involve returning specific error codes, queueing requests, or simply dropping them. The goal is to protect the core functionality and prevent catastrophic collapse, even if it means some users experience degraded service or temporary unavailability. It's a pragmatic acceptance that survival sometimes means triage.
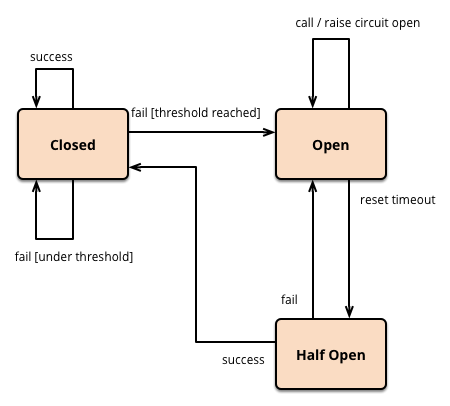
These patterns are not patches; they are architectural choices rooted in a pessimistic realism. They operate on the assumption that every remote call might fail, every network might glitch, every resource might vanish, and every client might misbehave. And by assuming the worst, they equip our systems to be profoundly resilient when the worst inevitably materializes.
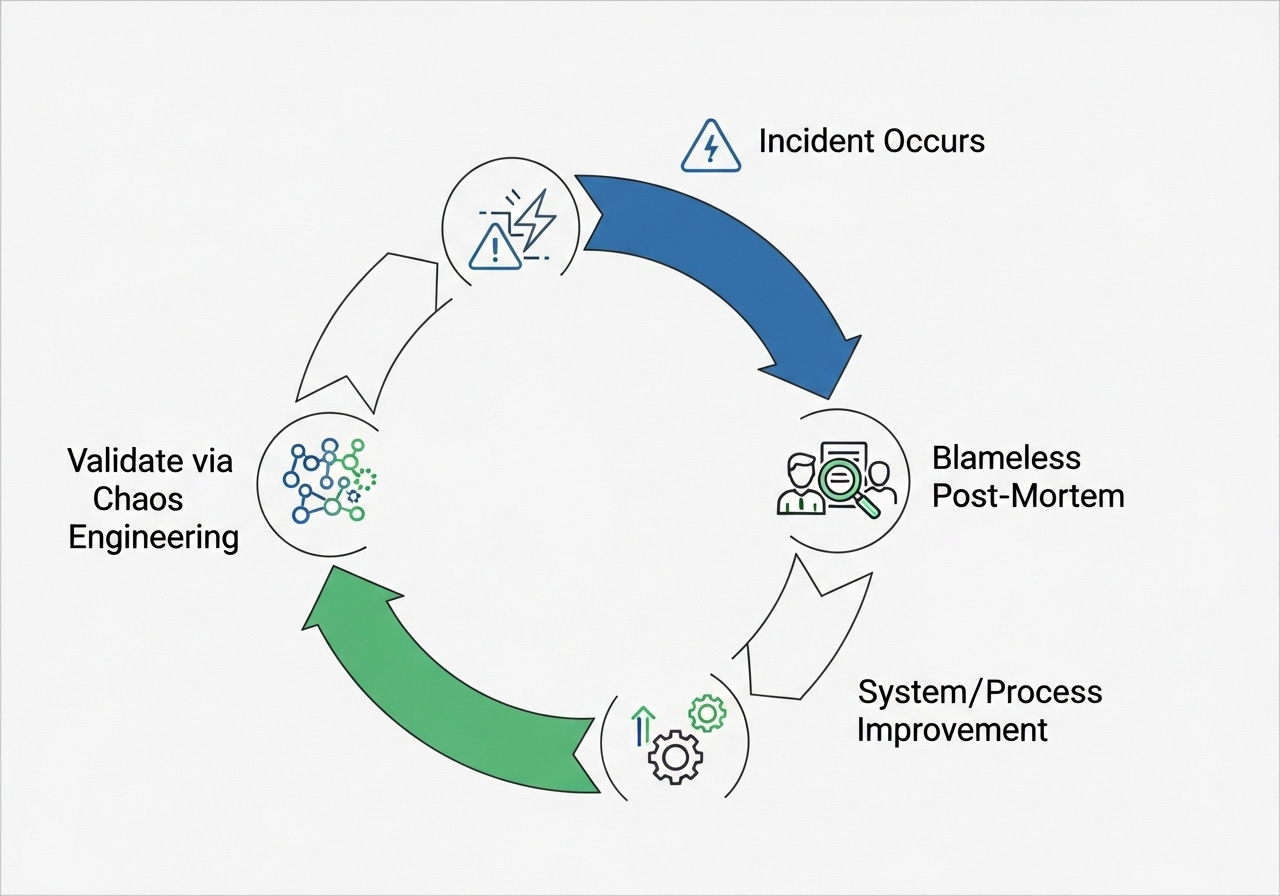
Practicing Failure: The Art of Chaos Engineering
Theoretical resilience is an oxymoron. Resilience, like any muscle, must be exercised. This is where Chaos Engineering enters the scene, evolving from the initial concept of Netflix's Chaos Monkey into a mature discipline. Its premise is simple: if you don't deliberately break your system, it will break on its own terms, likely at the most inconvenient time.
Chaos Engineering is about systematically injecting faults into production environments to validate resilience mechanisms and, crucially, to train teams.
Hypothesize: define a steady state for your system (e.g., "users should be able to add items to their cart").
Experiment: introduce a controlled fault (e.g., "take down a specific instance of the inventory service").
Observe: monitor the system's behavior. Did the system remain in a steady state? Did the resilience patterns (circuit breakers, fallbacks) kick in as expected?
Learn: if the system deviated from the steady state, understand why and implement fixes.
These experiments are often conducted during planned Game Days – dedicated events where teams simulate outages and practice their incident response. Injecting faults could involve:
Killing servers/processes: directly terminating instances of services.
Causing traffic spikes: overloading services with synthetic load.
Slowing responses: introducing artificial latency into network calls.
Resource exhaustion: depleting CPU, memory, or disk space.
Network partitioning: isolating parts of the network to simulate outages.
The objective of Chaos Engineering is not to achieve "uptime at any cost" but to build confidence. Confidence that when failures inevitably occur, both the automated systems and the human operators behind them possess the knowledge, tools, and muscle memory to respond effectively.
Graceful Degradation: The Art of the Less-Than-Perfect
True resilience also demands a commitment to graceful degradation. A system cannot always be at 100% functionality. When critical dependencies are unavailable, the intelligent system doesn't simply crash; it offers alternative, reduced functionality. This is about prioritizing core user journeys and acknowledging that a partially functioning system is infinitely superior to a completely dead one.
Fallback strategies include:
Serving cached or static content: if a real-time data source is down, display the last known good data or generic content rather than an error page.
Switching to reduced functionality: an e-commerce site might allow browsing products but disable adding to cart if the inventory service is unavailable, or switch to a read-only mode if the primary database is experiencing issues.
Communicating transparently: rather than ambiguous "server error" messages, inform users what's happening and what functionality might be affected.
Observability's Role: Seeing in the Dark
None of these resilience mechanisms function effectively in a black box. Observability is a non-negotiable prerequisite for building, validating, and operating resilient distributed systems. When chaos inevitably strikes, detailed insights into system behavior are the only way to diagnose, understand, and rectify issues.
The pillars of observability – logs, metrics, and distributed traces:
Logs: provide discrete, timestamped events. They tell you what happened at a specific point in time (e.g., "Circuit breaker tripped for payment service," "Retry attempt #3 initiated").
Metrics: aggregate numerical data over time. They tell you how much or how often something is happening (e.g., "Error rate for service X," "Latency of database queries," "Number of open circuit breakers"). Metrics are crucial for identifying trends and detecting anomalies.
Distributed Traces: visualize the flow of a single request across multiple services. They tell you where a request spent its time, which services it called, and where it failed. This is invaluable for pinpointing bottlenecks and cascading failures in complex microservice architectures.
Without robust observability, resilience patterns are just theoretical constructs. You won't know if your timeouts are firing, if your retries are creating a thundering herd, or if your circuit breakers are effectively protecting downstream services. Observability provides the feedback loop essential for continuous improvement and the hard data needed for post-incident analysis.
The Cultural Layer: Beyond the Code
Ultimately, resilience is profoundly cultural. The most robust technical patterns will crumble under a dysfunctional team dynamic. Teams that resort to individual blame after outages learn nothing. Instead, they foster fear and inhibit the sharing of critical information.
The hallmark of a resilient culture is the blameless post-mortem. This practice shifts the focus from "who caused the failure?" to "what were the systemic factors that allowed this failure to occur, and how can we prevent similar incidents in the future?" By documenting assumptions, challenging existing mental models, and treating every failure as a rich source of data, teams create powerful feedback loops. This is where Woods's fourth pillar, sustained adaptability, truly lives: not in lines of code, but in the collective learning and evolving practices of a high-performing engineering organization.
Conclusion
The old engineering dream of eliminating failure, while noble in some domains, is not only inapplicable but actively harmful in distributed systems. Here, failure is not the enemy; fragility is. By embracing the inevitability of chaos, through the deliberate application of defensive patterns, the rigorous practice of chaos engineering, the thoughtful design for graceful degradation, the presence of observability, and the cultivation of a resilient culture, we transform chaos from a threat into a teacher.
True resilience is not about constructing systems that never fail. It is about building systems – and, more importantly, the teams that operate them, that emerge stronger, wiser, and more capable every single time they do.