
How the Gemini Robotics family translates foundational intelligence into physical action
AGI and the barrier of embodied reasoning

The modern trajectory of artificial intelligence has been a story of rapid ascent, but one largely confined to the digital sphere. We have witnessed immense computational power unlock complex reasoning across text and imagery. However, the path to creating truly general-purpose autonomous AI—systems capable of operating robustly and reliably in the physical world—demands a fundamental transformation. This transition requires overcoming the crucial challenge of embodied reasoning (ER): the complex set of world knowledge encompassing spatial understanding, intuitive physics, and inter-object relationships that are foundational for physically grounded agency.

The latest iteration of this effort, the Gemini Robotics 1.5 family of models, represents a cohesive architectural step toward addressing this challenge head-on, significantly extending the capabilities of prior systems. This family, comprising the Gemini Robotics-ER 1.5 (VLM) and Gemini Robotics 1.5 (VLA), takes a definitive step toward enabling robots to perceive, reason, and act to solve highly complex, multi-step tasks in unstructured environments.

This essay explores the core technical innovations—the dual agentic architecture, the thinking VLA framework, and the multi-embodiment motion transfer mechanism—that underpin this push toward generalist physical agents.
I. The dual architecture for intelligence and action
The physical world demands adaptability and long-horizon planning, requirements that strain monolithic robotic architectures. The Gemini Robotics approach solves this by implementing a Dual Agentic System Architecture, separating the roles of high-level intellect (orchestration) and low-level execution. This framework is critical for handling complex, multi-step tasks that require contextual information and sequential completion.
The orchestrator: Gemini Robotics-ER 1.5 (The VLM brain)
The Gemini Robotics-ER 1.5 model functions as the high-level brain, or orchestrator, controlling the overall flow of the task. This Vision-Language-Model (VLM) is optimized for complex embodied reasoning problems such as task planning, reasoning for spatial expertise, and task progress estimation.
High-level planning and tool use: GR-ER 1.5 excels at planning and making logical decisions within physical environments. To tackle tasks that require external information—such as determining local recycling guidelines based on location—the orchestrator can natively call tools like Google Search or any third-party user-defined functions.
Adaptive orchestration: the orchestrator processes user input and environmental feedback. It breaks down complex tasks into simpler steps that the VLA can execute. For example, asked to “Pack the suitcase for a trip to London,” the orchestrator might access a travel itinerary or weather forecast to decide which clothes are appropriate to pack, then produce a high-level instruction like “pack the rain jacket into the luggage”.
Advanced sensing: GR-ER 1.5 achieves state-of-the-art performance on spatial understanding and is the first thinking model optimized for embodied reasoning. It evaluates task progress and detects success to determine when to advance to the next step.

The Action model: Gemini Robotics 1.5 (The VLA hand)
The Gemini Robotics 1.5 model is the Vision-Language-Action (VLA) model responsible for execution. It translates instructions issued by the orchestrator into direct, low-level robot actions. GR 1.5 is a derivative of Gemini fine-tuned to predict robot actions directly and enables general-purpose robot manipulation across different tasks, scenes, and multiple robots.
II. Thinking before acting
A critical architectural breakthrough in Gemini Robotics 1.5 is the implementation of Embodied Thinking—the ability for the model to explicitly reason or “think” before taking physical action. Traditionally, VLA models translated instructions or linguistic plans directly into movement. The Thinking VLA (GR 1.5, with thinking mode ON) now interleaves actions with a multi-level internal monologue of reasoning and analysis articulated in natural language.
Mechanism and performance gains:
Task decomposition: this process simplifies the challenging cross-modal translation (mapping complex language goals to low-level actions) into two easier stages. The model converts complex tasks into sequences of specific, short-horizon, language-based steps. For instance, when asked to “Sort my laundry by color,” the Thinking VLA first understands the semantic goal (”putting the white clothes in the white bin”), and then plans the detailed motion (”moving a sweater closer to pick it up more easily”).
Robustness to complexity: this decomposition dramatically improves the model’s capacity to handle multi-step tasks, resulting in a sizable improvement in the progress score for multi-step benchmarks compared to the model without thinking enabled.
Situational awareness and recovery: the Thinking VLA gains an implicit awareness of its progress, eliminating the need for a separate success detector. This enables sophisticated recovery behaviors; if an object slips from the gripper (e.g., a water bottle lands near the left hand), the next thinking trace instantly generates a self-correction (e.g., “pick up the water bottle with the left hand”).
Transparency: by generating its internal analysis in natural language, the Thinking VLA makes the robot’s decisions and plan execution transparent and more interpretable to human users.

III. Scaling the physical world: generalization and motion transfer
General-purpose robotics has long been hampered by the data scarcity problem and the sheer difficulty of transferring skills between robots of different forms and sizes. Gemini Robotics 1.5 addresses this by integrating a Motion Transfer (MT) mechanism and novel architecture within its pre-training process.
Multi-Embodiment Learning
GR 1.5 is designed as a multi-embodiment VLA model, trained on heterogeneous data from various robot platforms. This foundational approach allows the model to learn a unified understanding of motion and physics.
Universal control: the same model checkpoint can successfully control dramatically different form factors, including the ALOHA robot, the Bi-arm Franka robot, and the Apollo humanoid robot, without requiring robot-specific post-training.
Zero-shot transfer: the MT mechanism is crucial for enabling the model to learn from diverse robot data sources and facilitating zero-shot skill transfer from one robot to another. For instance, skills identified in ALOHA data, such as closing a precise pear-shaped organizer, can be transferred and executed successfully by the Bi-arm Franka robot. The MT training recipe is specifically noted for amplifying the positive effect of multi-embodiment data.
Rapid adaptation: this learned foundational knowledge enables rapid task adaptation for new, short-horizon tasks, requiring as few as 50 to 100 demonstrations for fine-tuning to reach high success rates.
Robust generalization capabilities
The high-capacity VLM backbone combined with diverse training data yields strong generalization performance across multiple axes:
Visual generalization: the system is robust to changes in the visual scene that do not affect the task, such as adding novel distractor objects, replacing the background (e.g., with a blue-white cloth), or changing lighting conditions.
Instruction generalization: the model understands the intent behind language even when instructions contain typos (”Put the top lft gren grapes...”), are rephrased, or are expressed in a new language (e.g., Spanish/Castilian, such as “Coloque las uvas verdes...”).
Action generalization: it can adapt learned motions to handle variations in object instances (e.g., folding different dress sizes) or unusual initial conditions.
Task generalization: this is the most comprehensive form of generalization, demonstrating the ability to successfully execute entirely new tasks in new environments, requiring robustness across all other axes simultaneously.
IV. Specialized dexterity and real-world agency
The synthesis of advanced reasoning and generalized action capability enables Gemini Robotics to achieve mastery over tasks demanding extreme dexterity and long-horizon execution.
Long-horizon dexterity: Gemini Robotics can tackle notoriously challenging, multi-step tasks requiring precise manipulation, such as origami folding or packing a snack into a Ziploc bag. When specialized through fine-tuning, the model demonstrates exceptional performance, including achieving a 100% success rate on the full long-horizon lunch-box packing task, which typically takes over two minutes to complete.
Advanced semantic reasoning: the system demonstrates sophisticated contextual understanding necessary for agency. For example, GR-ER 1.5 can successfully execute instructions involving novel semantic concepts like identifying the “Japanese fish delicacy” (sushi) among distractors, or understanding relative spatial size concepts like packing the “smallest coke soda”.
Physical constraint reasoning: GR-ER 1.5 can follow complex pointing prompts that require reasoning about physical constraints, such as identifying objects a robot is physically able to pick up based on a given payload (e.g., 10lbs). It can also generate trajectories that actively avoid collisions.
V. Embodied reasoning and safety
The power of a generalist physical agent necessitates a robust and comprehensive safety framework. The development of the Gemini Robotics models strictly adheres to the Google AI Principles.
State-of-the-Art Embodied Reasoning (GR-ER 1.5)
GR-ER 1.5 significantly advances the state-of-the-art for reasoning capabilities critical for robotics. It was evaluated on 15 academic benchmarks, including Embodied Reasoning Question Answering (ERQA) and Point-Bench. ERQA specifically measures abilities like spatial reasoning, trajectory reasoning, and action reasoning.
Reasoning-enhanced performance: GR-ER 1.5 establishes a new state-of-the-art on these benchmarks. Crucially, its performance is enhanced when incorporating Chain-of-Thought (CoT) prompting, which encourages the model to output step-by-step reasoning traces before committing to an answer. This thinking process scales better with inference-time compute for embodied reasoning tasks compared to generic models like Gemini 2.5 Flash.
Success and progress estimation: GR-ER 1.5 excels at capabilities like task planning, progress estimation, and success detection—essential functions for robot autonomy.

The holistic safety framework
The hybrid digital-physical nature of these models requires a specialized, multi-layered safety perspective. The holistic approach includes:
Safe human-robot dialogue: by building on the base Gemini checkpoints, the models inherit safety training ensuring alignment with Gemini Safety Policies, preventing the generation of harmful conversational content (e.g., hate speech, inappropriate advice).
Physical action safety: this addresses traditional robotics concerns, ensuring the VLA models are interfaced with classical, low-level safety-critical controllers for hazard mitigation, collision avoidance, and force modulation.
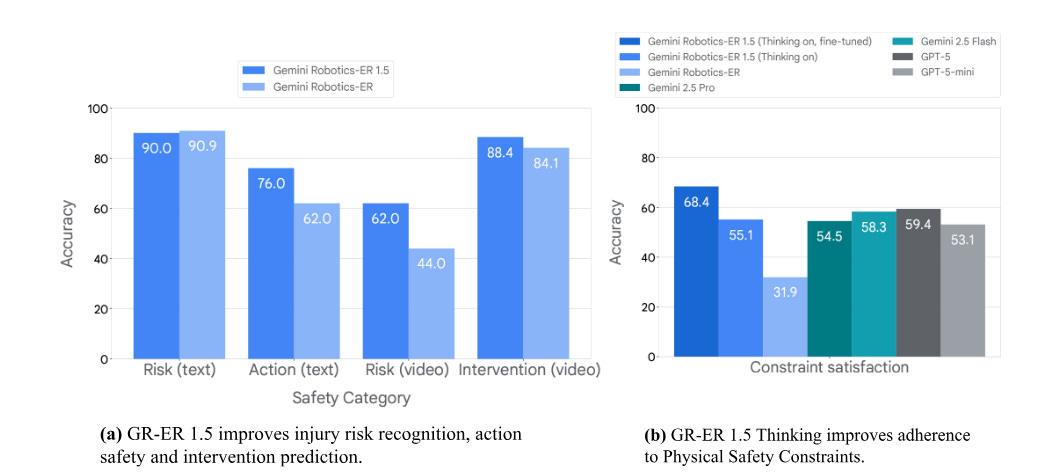
Semantic action safety: this addresses the “long-tail” of common-sense rules essential for operating in human-centric environments. Examples include preventing the robot from placing a soft toy on a hot stove or serving peanuts to an allergic person. This is improved through explicit safety reasoning (Thinking about Safety).
Evaluation: semantic safety is evaluated using the specialized and upgraded ASIMOV-2.0 benchmark. This benchmark incorporates data based on real-world injury scenarios sourced from the NEISS records. GR-ER 1.5 demonstrates improved performance in recognizing risks and understanding the safety consequences of actions compared to earlier models.
VI. Conclusion: the critical path to physical AGI
The Gemini Robotics 1.5 family represents a significant push toward unlocking general-purpose robotics. The integration of the highly specialized Gemini Robotics-ER 1.5 orchestrator and the multi-embodiment Gemini Robotics 1.5 executor validates an important design philosophy: reliable physical agents require the combination of high-level, generalized embodied reasoning with robust low-level control.
By pioneering the Thinking VLA for superior task decomposition and error recovery, and implementing the Motion Transfer mechanism to accelerate learning across platforms like ALOHA, Franka, and Apollo, this work systematically addresses the fundamental challenges of generalization and data scarcity that have historically plagued the field.
The capabilities demonstrated—state-of-the-art embodied reasoning performance, rapid task adaptation with few demonstrations, and robust, multi-layered safety mechanisms grounded in semantic understanding—define the critical path toward deploying truly general and capable AI agents in the physical world.
References
Gemini-Robotics-Team et al. (2025). Gemini Robotics: Bringing AI into the Physical World. arXiv preprint arXiv:2503.20020
Gemini-Robotics-Team et al. (2025). Gemini Robotics 1.5: Pushing the Frontier of Generalist Robots with Advanced Embodied Reasoning, Thinking, and Motion Transfer. Technical Report, Google DeepMind
Sermanet, P., et al. (2025). Generating Robot Constitutions & Benchmarks for Semantic Safety. Conference on Robot Learning (CoRL) 2025
Gemini-Team et al. (2023). Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805