
Heart, Nerves, and Bones: The Architectural Roles of Kafka, NATS, and ZeroMQ
A practical guide to choosing between durable logs, message buses, and raw sockets.

A distributed system is a living thing. Its messaging layer is not a simple library, but a vital organ: a stateful, failure-prone, and deeply opinionated architectural boundary. The choice of this system encodes not just how components communicate, but how the entire application evolves, recovers, and scales.
To build a resilient architecture, it helps to see these systems for their distinct biological roles. Are you building the durable Heart, the responsive Nervous System, or the foundational Bones?
This distinction is the key to understanding the deep philosophical and technical differences between Kafka, NATS, and ZeroMQ. In this breakdown, we will dissect each one, exploring its features, its core assumptions, and how those assumptions will shape everything you build on top of them.
Kafka: The Log-Centric Heart of Modern Data Architectures
Kafka’s primary abstraction is a partitioned, replicated, and distributed log. This simple but powerful concept is the foundation for its role in enabling temporal decoupling, data replayability, and massive-scale stream processing.
Core Architecture: The Immutable Log
A Kafka topic is a logical category for events, physically realized as one or more partitions. Each partition is a strictly ordered, append-only sequence of records stored across one or more brokers.
Kafka guarantees that:
A record is appended to the end of a specific partition.
Each record within a partition is assigned a unique, sequential offset.
Consumers read from the log by requesting records from a specific offset.
This design creates temporal decoupling. A producer's only job is to write to the log; it is completely unaware of who consumes the data, or when.
Key Implication: The log becomes the central, immutable system of record. This decouples data storage from the compute logic that acts on it, enabling powerful patterns:
Replayability: a consumer can "rewind" to a past offset and re-process historical data.
Multi-Subscriber Independence: each consumer group tracks its own position (offset) in the log.
Replication and High Availability
To prevent data loss and ensure availability, each partition is replicated across multiple brokers using a leader-follower model.
Leader: handles all read and write requests for that partition.
Followers: passively synchronize data from the leader. If the leader fails, a follower is elected as the new leader.
Durability is configured by the producer via the acks (acknowledgments) setting:
acks=0: Fire-and-forget. No acknowledgment.acks=1. Leader Acknowledgment. Waits for the leader to write the record.acks=all. Full Acknowledgment. Waits for all in-sync replicas (ISR).
Key Implication: the acks setting represents a direct trade-off between durability and throughput/latency. acks=all provides the strongest guarantee against data loss but can reduce throughput.
The Scalability Trade-Off: Partitioning vs. Global Order
Kafka provides a strict ordering guarantee, but only within a single partition. There is no built-in support for global ordering across all partitions of a topic. To achieve ordering for related events, you must send them to the same partition using a partitioning key (e.g., a userId or orderId).
Key Implication: forgoing global ordering is what allows Kafka to scale horizontally. By splitting a topic into many partitions, throughput can be distributed across the entire cluster. Your application design must align with this reality.
Consumer Model and Delivery Semantics
Kafka uses a pull-based consumer model, where consumers poll the broker for new messages.
Consumer Groups: one or more consumers can form a group to jointly consume a topic. Kafka automatically distributes partitions among them.
Offset Management: consumers are responsible for committing their last-read offset.
Delivery Semantics: depend on when the consumer commits its offset.
At-least-once (Default): commit the offset after processing the message.
At-most-once: commit the offset before processing.
Exactly-once: possible via transactional APIs, but adds significant complexity.
Key Implication: The pull model gives consumers great flexibility but also greater responsibility. Developers must actively manage consumption logic and handle potential duplicates.
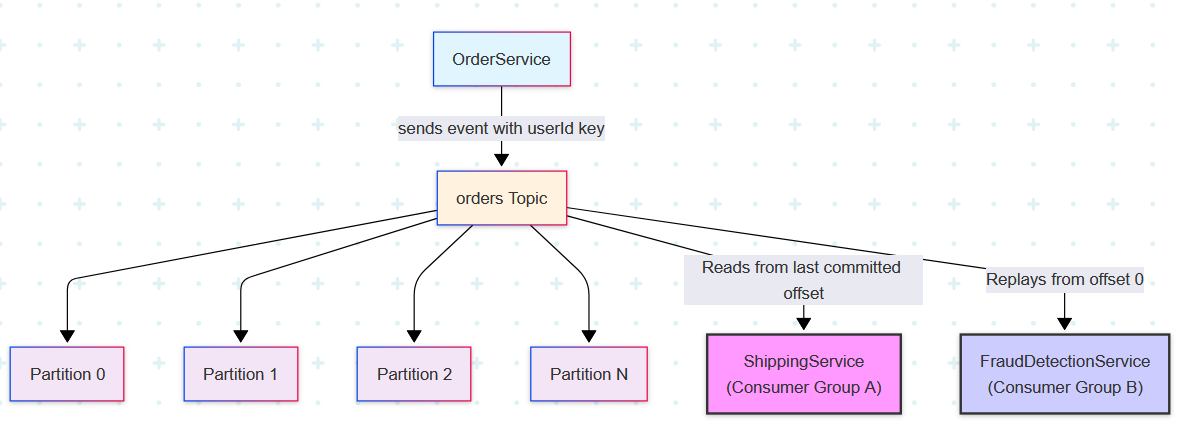
Practical Example: An E-Commerce Platform
Imagine an orders topic on an e-commerce platform.
The
OrderServiceproducesOrderPlacedevents. To ensure that all orders from a single customer are processed sequentially, it would use the userId as the partitioning key. For maximum durability, it would be configured with acks=all.A
ShippingServiceconsumes these events. Its code would be designed to manually commit offsets after successfully processing an order, implementing at-least-once delivery semantics.Months later, a new
FraudDetectionServicecould be deployed. It could be configured to start reading from the beginning of the orders topic, replaying the entire history to train its models without ever disrupting the liveShippingService. This demonstrates the power of temporal decoupling and replayability.
NATS: The Nervous System for Distributed Applications
NATS is designed with a radically different philosophy than Kafka. It prioritizes being a lightweight, high-performance, and flexible "nervous system" for distributed applications. Its core is built for real-time, low-latency, in-memory messaging, with optional persistence and durability added via its JetStream component.
Core NATS: In-Memory, Subject-Based Messaging
Unlike Kafka's rigid topic and partition model, Core NATS uses flexible, hierarchical subjects. A subject is simply a string that provides context, like "orders.us.new" or "telemetry.drone-123.temp".
This model is powered by an in-memory radix tree on the server, which performs highly efficient subject matching. It enables powerful and dynamic communication patterns natively in the protocol:
Publish/Subscribe: a publisher sends a message to a subject, and all active subscribers receive it.
Queue Groups: multiple subscribers can join a queue group. NATS will randomly select one member of the group to receive each message, enabling effortless load balancing.
Request/Reply: a requester sends a message on a subject and waits for a response on a temporary, unique "reply" subject. This builds RPC-style communication directly into the messaging layer.
Subscribers can use wildcards to listen to multiple subjects at once:
* (star) matches a single token: orders.*.new matches orders.us.new and orders.eu.new.
> (greater than) matches one or more tokens at the end: telemetry.drone-123.> matches telemetry.drone-123.temp, telemetry.drone-123.gps, etc.
Key Implication: NATS promotes a dynamic and discoverable topology. Services don't need to know about pre-configured topics or partitions. They just need to agree on subject naming conventions. This makes it incredibly fast to develop and evolve microservices that can communicate in complex ways without rigid infrastructure changes.
NATS JetStream: Adding Persistence and Durability
Core NATS is "fire-and-forget." If no subscriber is listening, the message is gone forever. JetStream is the persistence layer built into the NATS server to provide Kafka-like guarantees.
Streams: A stream captures messages from one or more subjects (wildcards are supported) and stores them. This is the rough equivalent of a Kafka topic. Streams have configurable retention policies (time, message count, or size).
Consumers: To read from a stream, you create a consumer. Durable consumers are key, as they track their progress, allowing them to stop and restart without losing their place. This is the equivalent of a Kafka consumer group.
JetStream uses a write-ahead-log (WRL) for storage and Raft for clustering and replication, ensuring high availability. However, it makes different trade-offs than Kafka:
At-Least-Once Delivery: the standard guarantee, achieved by requiring consumers to explicitly acknowledge (ack) each message. If an ack is not received, JetStream will redeliver the message.
No Built-in Exactly-Once: deduplication (handling redelivered messages) is the responsibility of the application, often using an idempotency key within the message payload.
Cursor-Based Replay: consumers replay based on a sequence number or timestamp, not an offset.
Key Implication: JetStream allows you to selectively add durability where you need it. You can use ephemeral Core NATS for high-volume telemetry and persistent JetStream streams for critical business events like orders, all within the same cluster and using the same client library.
Flow Control and Backpressure
As a primarily push-based system, NATS requires proactive flow control from the consumer.
Core NATS: if a subscriber's connection buffer is full, the server will drop messages for that subscriber.
JetStream: provides robust flow control. A consumer declares how many unacknowledged messages it is willing to have "in-flight" at once (max_ack_pending). The server will not push more messages until the consumer ack's previous ones, effectively creating backpressure.
Key Implication: the burden of managing message flow is on the consumer's configuration. Unlike Kafka's ever-growing lag, an overwhelmed JetStream consumer will simply stop receiving new messages until it catches up, which is easier to reason about but requires careful tuning of max_ack_pending.
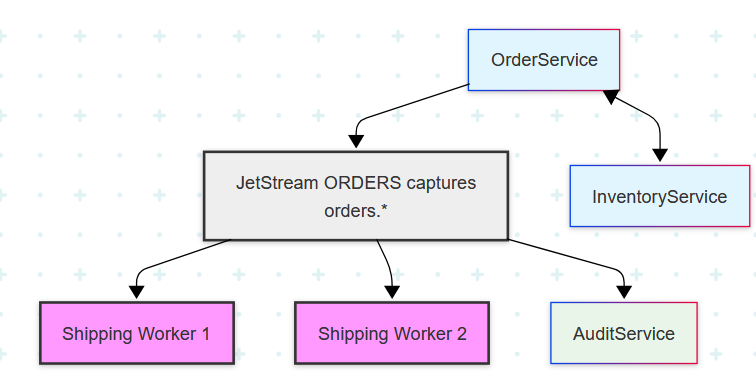
Practical Example: An E-Commerce Platform with NATS
Let's adapt the e-commerce scenario to NATS, showcasing its unique features.
Scenario:
To place an order, the
OrderServicewould first use the built-in request/reply pattern to send a message to theinventory.checksubject. AnInventoryServicewould listen, check its database, and send a response back.If inventory is available, the
OrderServicewould then publish anOrderPlacedevent to a JetStream stream on theorders.placedsubject.To process these orders, multiple instances of a
ShippingServicewould subscribe toorders.placedusing the same queue group name. NATS would automatically load-balance the orders between the running instances.Simultaneously, an
AuditServicecould use a wildcard subscription (orders.*) to get a copy of every order-related event for logging, demonstrating the flexibility of subject-based routing.
ZeroMQ: The Un-Broker and Foundational Bones for High-Performance Networking
ZeroMQ (ØMQ) is not a messaging system in the same vein as Kafka or NATS. It is not a broker, has no server, and provides no persistence or durability. Instead, ZeroMQ is a high-performance, asynchronous messaging library, a concurrency toolkit disguised as a socket.
Its philosophy is to provide developers with powerful communication patterns as primitives, allowing you to build complex, custom network topologies without needing a centralized broker.
Socket Types Define the Architecture
ZeroMQ's magic lies in its specialized socket types. When you create a ZeroMQ socket, you are not just opening a network connection; you are choosing a built-in messaging pattern.
REQ/REP (Request-Reply): a strict, lock-step pattern for simple RPC. The client must send() then recv(), and the server must recv() then send().
PUB/SUB (Publish-Subscribe): a one-to-many data distribution pattern. Publishers are oblivious to subscribers. A key weakness is the "slow subscriber problem": if a subscriber cannot keep up, messages are silently dropped.
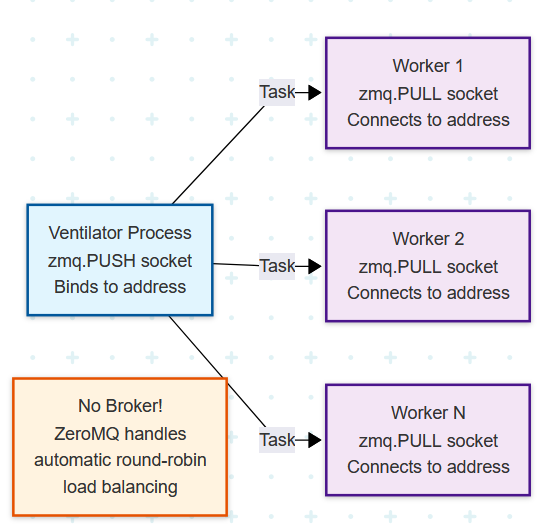
PUSH/PULL (Pipeline): a pattern for distributing a stream of work. A PUSH socket sends messages to a set of PULL sockets, which are automatically load-balanced. Ideal for task distribution and parallel processing pipelines.
DEALER/ROUTER (Asynchronous Req/Rep): the advanced, non-blocking versions of REQ/REP. They allow for fully async, multi-part, and routed communication, forming the basis for building more complex brokers and protocols.
Key Implication: with ZeroMQ, the application developer is also the system architect, you are composing network behaviors directly in your code by choosing and connecting different socket types.
The Catch: You Are the Broker
ZeroMQ achieves its blazing speed and low latency by omitting nearly every feature a traditional message broker provides. When you choose ZeroMQ, you are explicitly taking on the responsibility for:
Persistence: messages exist only in memory. If a process crashes, its messages are gone.
High Availability: there is no clustering or leader election. You must design your topology to handle node failure.
Delivery Guarantees: selivery is not guaranteed. There are no acknowledgments or retries unless you build them into your application protocol.
Discovery and Routing: processes must know how to connect to each other (via IP/port). There is no central registry.
Monitoring: there is no "consumer lag" or "stream backlog" to monitor. You must build your own health checks and heartbeats.
Backpressure is handled at the socket level via a High-Water Mark (HWM). Once a socket's internal queue is full, it will either block or drop subsequent messages, depending on the socket type.
Key Implication: ZeroMQ is the ideal choice for performance-critical applications within a controlled environment (e.g., inter-process communication on one machine, or services in the same data center rack). It is a poor choice for systems that cross unreliable networks or require strong durability and replayability, as you would end up rebuilding a broker from scratch.
Final Thoughts: Choosing Your System's Nervous System
Kafka, NATS, and ZeroMQ are not interchangeable because they solve fundamentally different problems at different layers of the stack.
Choose Kafka when your data is a valuable, replayable asset. It acts as the immutable, durable heart of an event-driven architecture.
Choose NATS when you need a flexible, high-performance communication fabric. It is the nervous system for coordinating distributed services with optional durability where it counts.
Choose ZeroMQ when you need to craft a custom, high-performance transport protocol. It gives you the raw power to define how bytes flow between processes, without the overhead or constraints of a broker.
In the end, the key is to make a deliberate choice. Don't just pick the fastest tool; pick the one whose architecture best matches your application's requirements for reliability, data guarantees, and future flexibility.