

A user types a question into your chat product. The question is long — they pasted a 14-page contract and asked for the third clause to be summarised. Your serving stack does what every textbook tells it to do: it dispatches the request to a vLLM replica, which begins a forward pass over every token in the prompt to build the KV-cache. The pass takes 2.3 seconds. During those 2.3 seconds, the same replica is supposed to be generating one token at a time for 73 other users who are halfway through their own conversations. They are not. They are waiting. Their TPOT — the time between tokens they see appear on the screen — has just spiked from 38 ms to over a second, because the GPU that is serving them is busy serving one person reading a contract. By the time the contract user gets their first token, an hour’s worth of P99 latency complaints is sitting in your incident channel.
This is the prefill-decode interference problem, and for two years it was the price of doing business on GPU. People wrote it off as the nature of LLM serving. Then somebody noticed that the price had gotten silly. A single long prefill can inflate TPOT by 2 to 30× under realistic bursts — not a bug, but the consequence of treating two fundamentally different workloads as if they were the same workload. They are not. The architecture that fixes this is now eighteen months old in production, has been accepted into the CNCF, and is treated as the default at every scale that matters. If you are still running monolithic vLLM 0.5 on a single GPU pool, you are paying the 2-to-30× tax every day.
This is a migration playbook. Not a tour of the research literature, not a sales deck for a vendor. It’s the answer to a specific question: you have a working LLM serving stack today, the architecture has shifted underneath you, what do you do about it on Monday morning.
Two workloads in a trench coat
The reason a single GPU pool can’t serve both phases well is that prefill and decode are different kinds of work pretending to be the same kind of work. Prefill takes a prompt, runs a full forward pass over every input token at once, and produces the KV-cache that the decoder will read from. It is gloriously parallel and saturates the GPU’s tensor cores. Throughput is dominated by FLOPs. The bigger the prompt, the longer it takes; latency scales with input length.
Decode is the opposite shape. It reads the KV-cache the prefill produced and generates one output token at a time. Each step requires touching every cached key and value tensor in memory. The arithmetic is trivial — a few matrix-vector products — but the memory bandwidth is the wall. You are bottlenecked by how fast HBM can stream the KV-cache through the SM, not by how many FLOPs the SM can do. The only way to make decode efficient is to batch many concurrent sequences together so that the same memory traffic amortizes across many users.
Now put both phases on the same GPU pool with continuous batching and ask what happens when a long prefill shows up. The scheduler has two options. Pause ongoing decodes and run the prefill first — every existing user sees a TPOT spike. Or batch the prefill into the same iteration as the decodes — every user still sees a TPOT spike, because prefill is compute-bound and stretches the iteration long enough that decode tokens crawl. There is no third option. The interference is structural.
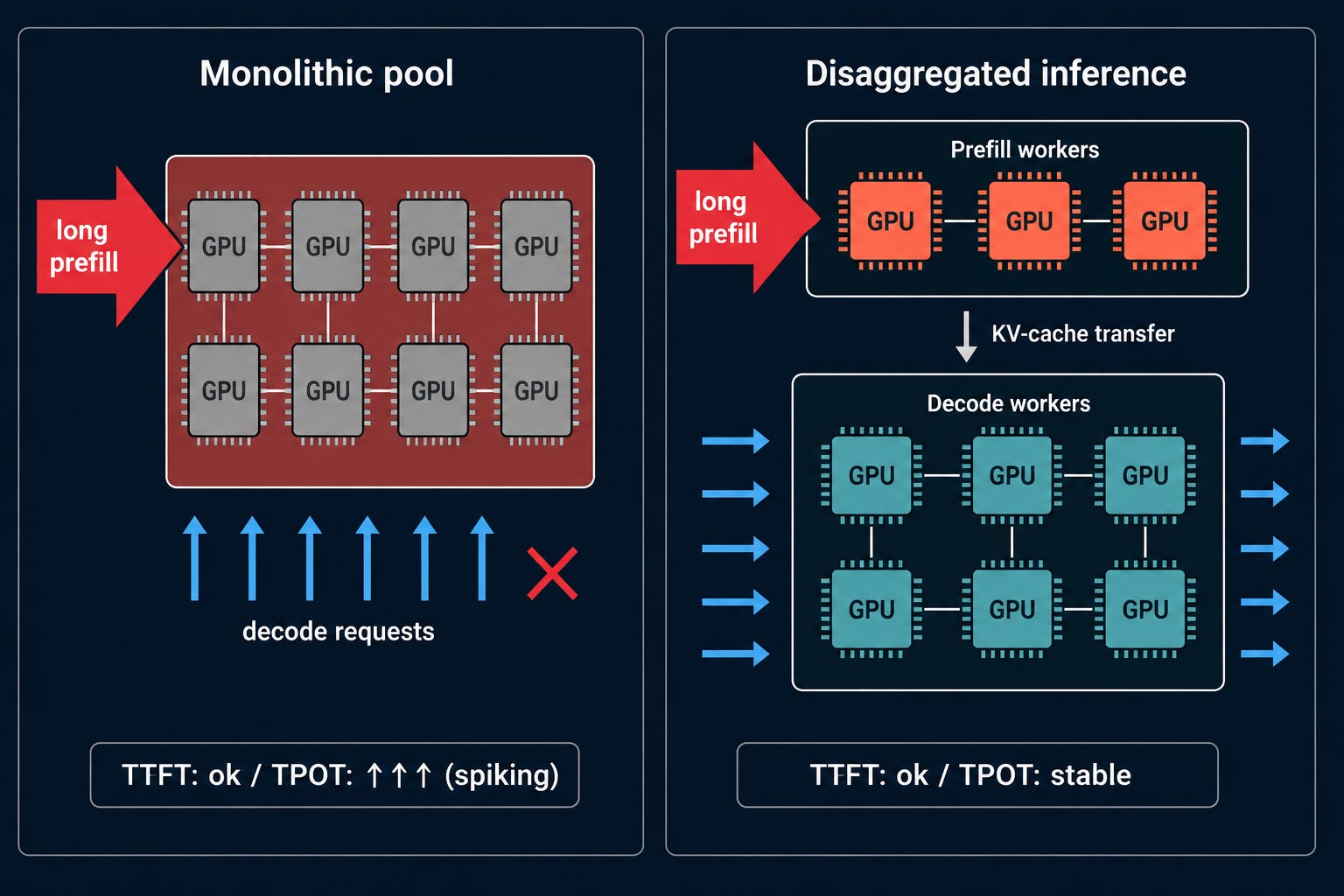
There is one mitigation worth understanding before the full fix. Chunked prefill — breaking a long prefill into smaller chunks interleaved with decode steps — is real, and for small-to-medium workloads it gets you a long way. But it has a quantitative failure mode: splitting prefill into N chunks requires reloading prior chunks’ KV-cache on each subsequent chunk, meaning O(N²) total KV-cache memory accesses instead of O(N). You also face a chunk-size dilemma — chunks below the GPU saturation threshold underutilize compute, chunks at the threshold leave no slots for piggybacked decode tokens. Chunked prefill is a 30–50% solution. Disaggregation is the 2–7× solution.
Who built the 2026 stack
The ecosystem converged in roughly twelve months. The stack choice — which orchestrator, which engine, which transport — is a secondary decision compared to deciding to migrate at all; below the orchestrator, the layers have converged on the same primitives and only the routing layer meaningfully differs.
At the orchestration layer there are three serious choices. NVIDIA Dynamo 1.0 (March 2026) runs on top of vLLM, SGLang, or TensorRT-LLM rather than competing with them; its two load-bearing pieces are a Planner that makes the disaggregate-or-aggregate decision at runtime, and a Distributed KV Cache Manager with a four-tier HBM→DRAM→SSD→object-store hierarchy. The headline benchmark — 30× throughput on DeepSeek-R1 671B — is a composite of disaggregation gains, wide expert parallelism inside an NVLink domain, and a long-context regime that favours P/D; the cleaner number is 2× on Llama 70B at 3K/50 sequence lengths on plain Hopper, which is closer to the pure disaggregation benefit on hardware you might actually own. The Kubernetes-native option is llm-d (CNCF Sandbox, March 2026): its two durable contributions are the Gateway API Inference Extension, which makes prefix-cache-aware routing a first-class Kubernetes primitive rather than an escape hatch, and LeaderWorkerSet, which handles multi-node replicas with proper lifecycle semantics. The third option is vLLM V1 with the Rust router — maximum control, minimum framework surface area, 25% higher RPS than llm-d on published benchmarks, no K8s dependency.
Below orchestration sits the KV-cache layer. LMCache, Mooncake, Dynamo’s KV Cache Manager, and Together AI’s CPD are all variations on the same idea: decouple the KV-cache lifecycle from the inference engine, pool it across nodes, let any prefill hand off to any decode. Mooncake’s prediction-based scheduler serves 75% more real requests under SLO pressure than a colocation baseline — the kind of number that quietly justifies an entire architecture.
The engine layer is vLLM V1, SGLang, or TensorRT-LLM, all with native P/D support as of late 2025. The transport layer is NVIDIA NIXL — Apache 2.0, a unified abstraction over NVLink, InfiniBand, RoCE, PCIe, and SSD. NIXL is the piece nobody outside the infra team notices and the piece that’s load-bearing for the stack. The DistServe paper’s most counterintuitive result follows from it: on OPT-175B with only 25 Gbps Ethernet, KV-cache transfer accounted for less than 0.1% of total request latency. The reason: a good placement algorithm keeps same-stage prefill and decode nodes together, so most transfers ride NVLink and only cross-stage transfers traverse the slow link. The conventional 10 GbE / 100 GbE breakpoint framing overstates how much raw bandwidth matters. Placement design dominates.
When not to disaggregate
The single most expensive failure mode in any migration is doing it before you need to. Disaggregation has real overhead — two pools to operate, a KV-transfer fabric to configure, a router that becomes a new point of failure, and a 10× increase in the surface area of “things that can go wrong at 3 a.m.” None of this is free. Disaggregation is the right answer at scale, not at any scale.
You should disaggregate when you’re serving above roughly a thousand requests per second, running reasoning models with long chains of thought, or handling long-context inputs like RAG over large document collections. You should disaggregate when you’re a multi-tenant platform with heterogeneous workloads — long prompts mixed with short ones, bursty traffic — or when your workload has repetitive prefixes that cluster-level prefix caching can compound. You should disaggregate when you’re GPU-constrained and want different hardware per phase: compute-dense GPUs for prefill, memory-bandwidth-optimized GPUs for decode.
You should stay monolithic when you’re serving low-traffic workloads, when inputs are uniformly short (consistently under 2K tokens), when you don’t have at least 10 GbE between nodes, or when your team doesn’t have the Kubernetes maturity for split-pool autoscaling. For the boundary case, chunked prefill first — it runs on a single node, requires zero new infrastructure, and gives you 30–50% of the benefit. If it solves your interference problem, you don’t need to migrate. The mistake is assuming the existence of a newer architecture obliges you to adopt it.
The migration, in order
Start by baselining your SLOs. Not your throughput. Measure TTFT at P50 and P99 under realistic load, and TPOT at P50 and P99, and write down what your SLA actually requires. A surprising number of teams discover they don’t have a real SLA, just a vibe that the system feels slow. Capture GPU utilization — below 60% you might not be GPU-constrained yet. If TTFT P99 is comfortably inside your SLA and TPOT P99 is stable, you don’t have an interference problem and disaggregation will not help you. This is the most important step, and the easiest one to skip.
If the baseline shows interference, try chunked prefill first. It’s a configuration change on vLLM V1, not an architectural change. Measure again. If the interference is gone, you’re done.
If chunked prefill isn’t enough, choose your stack. Kubernetes-native with multi-vendor accelerator support: llm-d. NVIDIA hardware with a managed Planner and NIXL integration: Dynamo. Maximum control, minimum framework surface area: vLLM V1 with the Rust router. None of these are wrong choices; the stacks are converging at the layers below the orchestrator.
Size your pools. The default starting ratio is 1:2 or 1:3 prefill-to-decode workers. A summarization workload (long input, short output) wants more prefill; a chatbot workload (short input, long output) wants more decode. Start with a workload-shaped guess and let the autoscaler converge.
Provision the KV-transfer fabric. Same-node pools ride NVLink and need nothing extra. Cross-node pools need InfiniBand or high-bandwidth Ethernet with NIXL. As established above, placement design dominates — the bandwidth requirement is more forgiving than you expect once colocation is right.
Monitor the right metrics: per-pool GPU utilization, prefill queue depth, decode batch fill rate, KV-cache transfer latency P99 (target under 50 ms), and prefix cache hit rate. The metric that catches failure modes early is prefix cache hit rate — if it falls, your router has lost cache locality and TTFT is about to rise. The metric that’s most often misleading is tokens per second: under SLO violations you can hit high throughput while serving requests that are useless to users. The metric that matters is goodput: requests per GPU served inside both TTFT and TPOT SLOs at a given attainment target.
The migration is mostly an organizational and observability problem. What’s hard is renegotiating your SLAs around two metrics instead of one, instrumenting them properly, and running a split-pool deployment on whatever Kubernetes story you already have. Plan for the operational lift, not the engineering one.
What breaks next
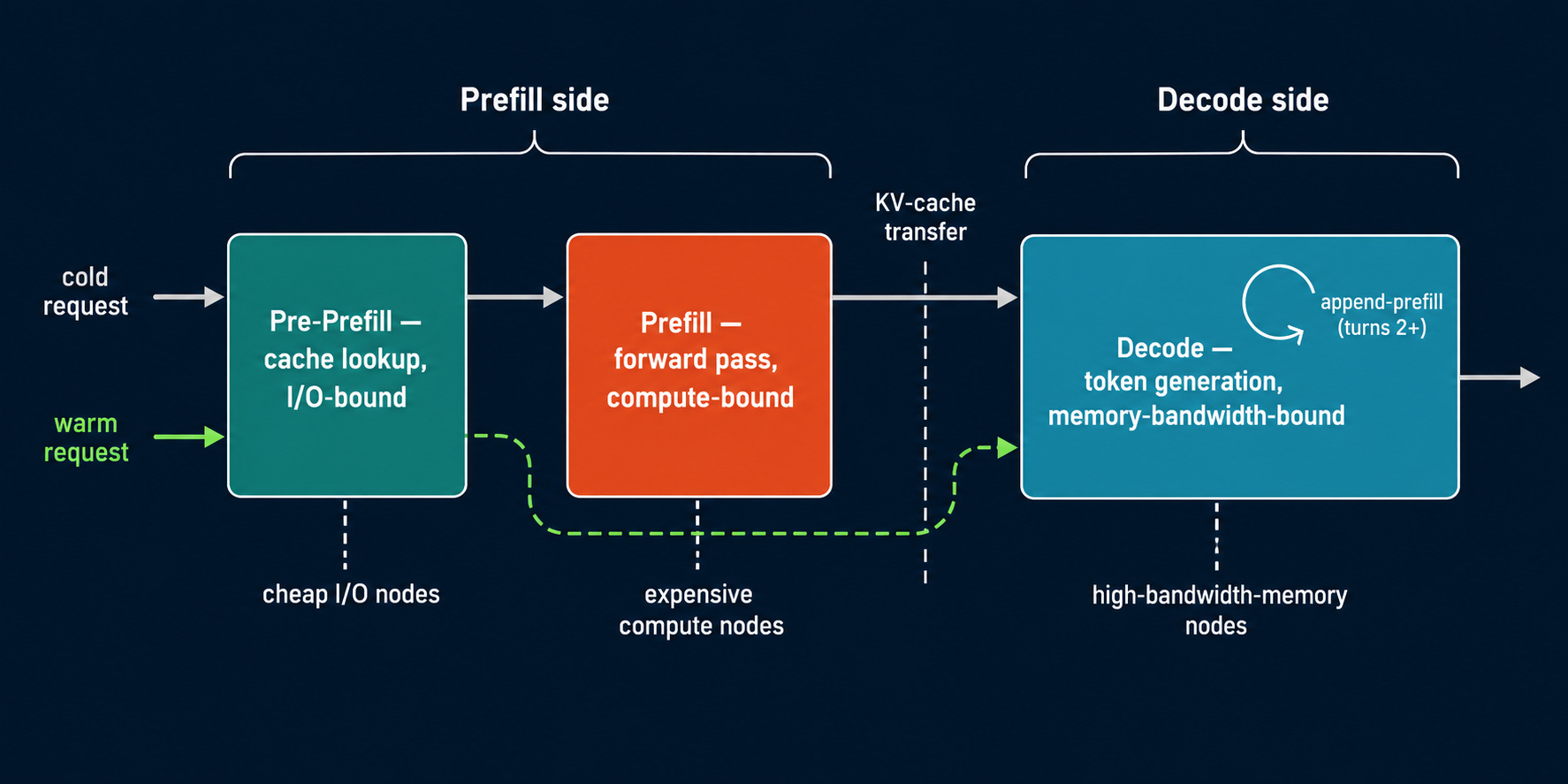
The cleanest signal that disaggregation has stopped being controversial is that researchers have moved on to critiquing it. The most important recent critique — “Not All Prefills Are Equal” (ICML 2026) — identifies a failure mode in standard P/D that dominates the dominant workload: multi-turn conversations. In a chatbot, Turn 2 arrives with a short new message but a long context that includes the response the decode node just generated. Vanilla P/D routes the entire context back through a prefill node, rebuilds the KV-cache from scratch, and ships it back to decode. Every turn after the first pays for a prefill it shouldn’t need and a KV transfer it shouldn’t make. PPD’s fix: keep the KV-cache local on the decode node and run cheap *append-prefills* — processing only new tokens against the existing cache — in line with ongoing decodes. The result on vLLM V1: 68% reduction in Turn 2+ TTFT with no TPOT regression, and the fabric saturation problem disappears.
Together AI’s CPD (March 2026) attacks the same problem from the prefill side. It splits prefill into two roles: Pre-Prefill, an I/O-bound phase for hash-based prefix matching and KV fetch from DRAM or RDMA; and Prefill proper, the compute-bound forward pass for uncached tokens only. Cold requests run Pre-Prefill→Prefill→Decode; warm requests skip Prefill entirely and run Pre-Prefill→Decode. The result is 35–40% throughput gain on long-context workloads on B200. The architectural pattern matters more than the number: separating the I/O-heavy lookup from the compute-heavy forward pass lets you provision cheap nodes for one and expensive nodes for the other.
CPD on the prefill side and PPD on the decode side compose into a four-role architecture: Pre-Prefill → Prefill → Decode, with decode handling its own append-prefills for turns 2+. That is almost certainly where this converges. The horizon beyond it is attention-FFN disaggregation — splitting within a single forward pass — and heterogeneous hardware, where decode runs on memory-bandwidth-optimized accelerators while prefill stays compute-dense. Neither is production-ready. Both are clearly coming. If you’re migrating now, you’re not building for 2026 — you’re building the foundation for what replaces it.
The dividing line
The dividing line in 2026 is not whether disaggregated inference is the right architecture. That question is settled. The dividing line is whether your workload is GPU-constrained at scale, because that is the only condition under which the architecture pays for itself. Below that line, monolithic vLLM with chunked prefill and aggressive prefix caching is a perfectly defensible production choice, and the engineering hours you’d spend migrating are better spent somewhere else. Above that line, you are paying the interference tax every minute you don’t migrate, and the ecosystem has converged enough that the choice of stack is a minor decision compared to the choice to migrate at all.
The thing I’d push back on is the framing where this decision is treated as exotic. It isn’t. It’s a routing problem, a placement problem, and an observability problem, all of which are problems your platform team has solved before for non-AI workloads. The Kubernetes-native stack — llm-d with GAIE and LWS — exists specifically so that you can apply the operational muscles you already have. The infrastructure is no longer the frontier. The frontier is whether you’ve measured your SLOs honestly enough to know which side of the line you’re on.
Sources
Zhong et al., DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving — USENIX OSDI 2024. arxiv.org/abs/2401.09670
Chen, Zhuang, Zhang (Hao AI Lab @ UCSD), Disaggregated Inference: 18 Months Later — November 2025. haoailab.com/blogs/distserve-retro
Elmeleegy et al. (NVIDIA), Introducing NVIDIA Dynamo — March 2025. developer.nvidia.com/blog/introducing-nvidia-dynamo
Costa, Coleman, Shaw, Welcome llm-d to the CNCF — March 2026. cncf.io/blog/2026/03/24/welcome-llm-d-to-the-cncf
vLLM Team, vLLM V1: A Major Upgrade to vLLM’s Core Architecture — January 2025. vllm.ai/blog/2025-01-27-v1-alpha-release
vLLM Team, vLLM Router: A High-Performance and Prefill/Decode Aware Load Balancer — December 2025. vllm.ai/blog/2025-12-13-vllm-router-release
Qin et al. (Moonshot AI / Tsinghua), Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving — USENIX FAST ‘25 Best Paper. arxiv.org/abs/2407.00079
Zhang et al. (Together AI), Cache-aware Prefill/Decode Disaggregation — March 2026. together.ai/blog/cache-aware-disaggregated-inference
NVIDIA AI-Dynamo team, NIXL — NVIDIA Inference Xfer Library — Apache 2.0. github.com/ai-dynamo/nixl
Li et al. (UChicago), Not All Prefills Are Equal: PPD Disaggregation for Multi-turn LLM Serving — ICML 2026. arxiv.org/abs/2603.13358