
AlphaEarth Foundations — A single, comprehensive breakdown
The embedding field that treats the planet as data infrastructure

The story of remote sensing has always carried a paradox. We live in an age of abundance: satellites, radar instruments, LiDAR, and ground stations pour out petabytes of observational data every year. Yet when we try to build reliable maps from that flood, we run into scarcity. Labels are sparse, geographically uneven, and expensive to collect. And even when labels exist, the pipelines are brittle: carefully crafted composites for vegetation, harmonics for seasonal cycles, hand-built models for every new task. Each map becomes a one-off engineering project.
AlphaEarth Foundations (AEF), a new release from DeepMind, reframes this problem in a single stroke. Instead of treating every mapping exercise as an independent pipeline, AEF builds a universal latent field, an embedding of the planet itself. Every 10×10 meter pixel of terrestrial surface is assigned a compact 64-dimensional vector. Those vectors are learned representations, trained across billions of heterogeneous observations — optical imagery, SAR, LiDAR, climate reanalyses, even text, with explicit conditioning on time.
The result is a planetary feature store. A single, queryable latent substrate on which downstream maps and analyses can be built.
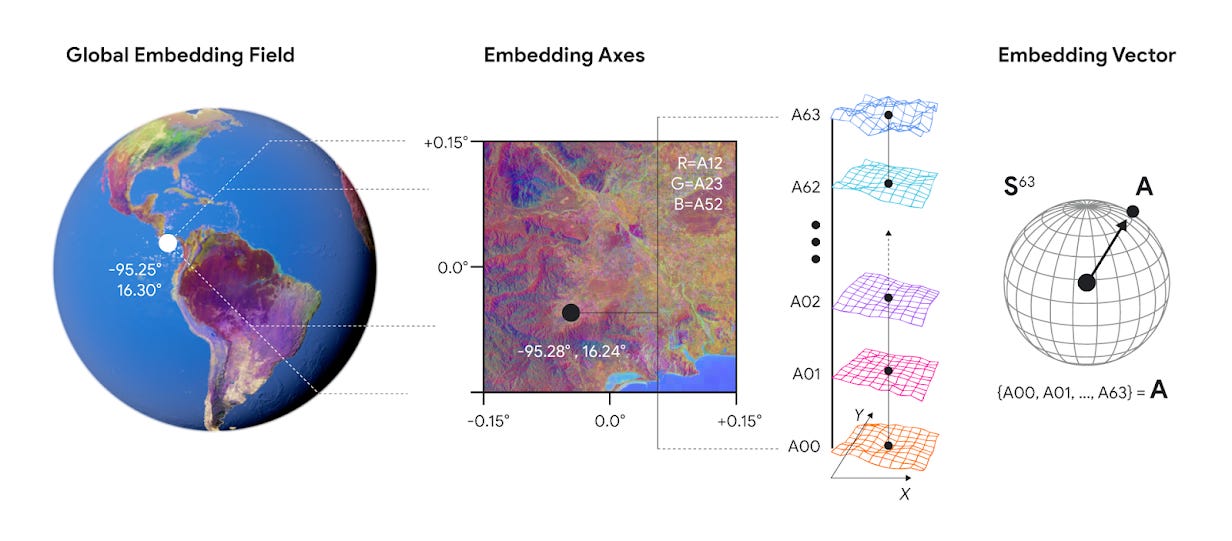
From abundance to embeddings
Customized, domain-specific models have been the foundation of geospatial analysis for many years. The characteristics and heuristics employed by one architect designing a crop-yield predictor and another designing a forest monitoring system were different. Handcrafted, delicate, and unable to capitalize on advancements in other disciplines, each pipeline was unique. Mutual information was trapped across sensor kinds and habitats.
AEF’s philosophy is a big shift. It posits that a single, foundational model, trained on a massive and diverse corpus of unlabeled data, can produce a universal set of features—an embedding—performant across a wide array of downstream tasks without re-training.
Three basic structural issues with Earth observation data are addressed directly by this design:
Multi-source & multi-modality. The system must handle the combination of different sensor types: optical bands, radar backscatter, LiDAR waveforms, climate reanalyses, even unstructured text.
Temporal inconsistency. Observations are sparse, irregular, and cloud-obscured. AEF must reconcile this into a continuous, time-indexed understanding of every location.
Extreme label scarcity. Labels are the scarcest resource in geospatial analysis. The model must learn powerful, semantic representations in a self-supervised fashion, effective even when ground-truth data is vanishingly small.
A data-flow breakdown
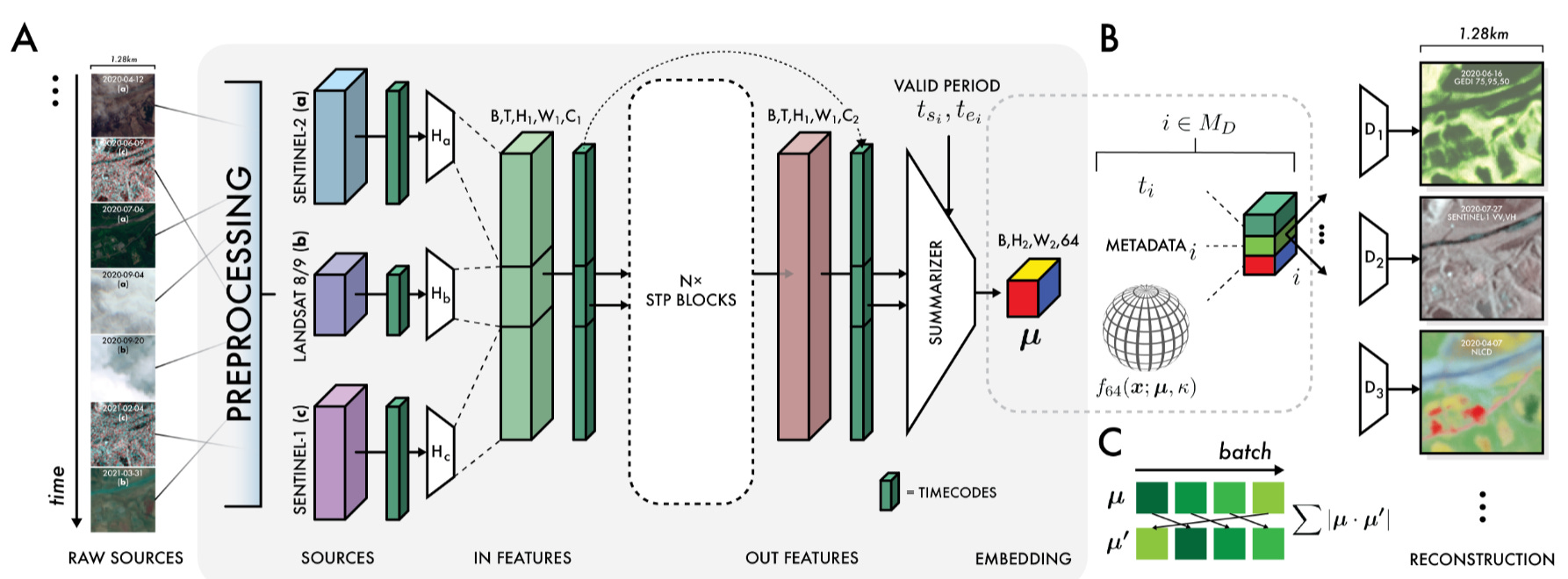
At its core, AEF is a sophisticated video processing pipeline that transforms raw, time-stamped satellite imagery into a dense, meaningful summary. We can understand its architecture by following the data.
Multi-modal inputs
Its strength begins with input diversity. The model is designed to ingest and assimilate a wide array of public Earth observation sources:
Optical imagery: Sentinel-2 (10–60 m) and Landsat 8/9 (15–100 m).
Synthetic Aperture Radar (SAR): Sentinel-1 (C-band) and ALOS PALSAR-2 (L-band), critical for penetrating clouds and capturing surface texture.
LiDAR: GEDI, providing canopy height and structural data for vegetation.
Environmental data: ERA5-Land climate reanalyses, GRACE gravity fields, and the GLO-30 digital elevation model.
Unstructured text: geocoded Wikipedia articles and GBIF species observations, offering a weak but useful source of semantic signals.
The Space-Time-Precision (STP) Encoder
At the heart of the system lies a novel encoder called Space Time Precision (STP). Standard vision transformers struggle with the sheer resolution and sequence length of EO data. STP is a pragmatic hybrid solution:
Space Operator: ViT-like spatial self-attention that captures relationships across a frame (fields, forests, rivers, cities).
Time Operator: time-axial self-attention that tracks the evolution of a single location across months and years (crop phenology, seasonal snow).
Precision Operator: simple 3×3 convolutions to preserve and process local spatial detail that attention often washes out.
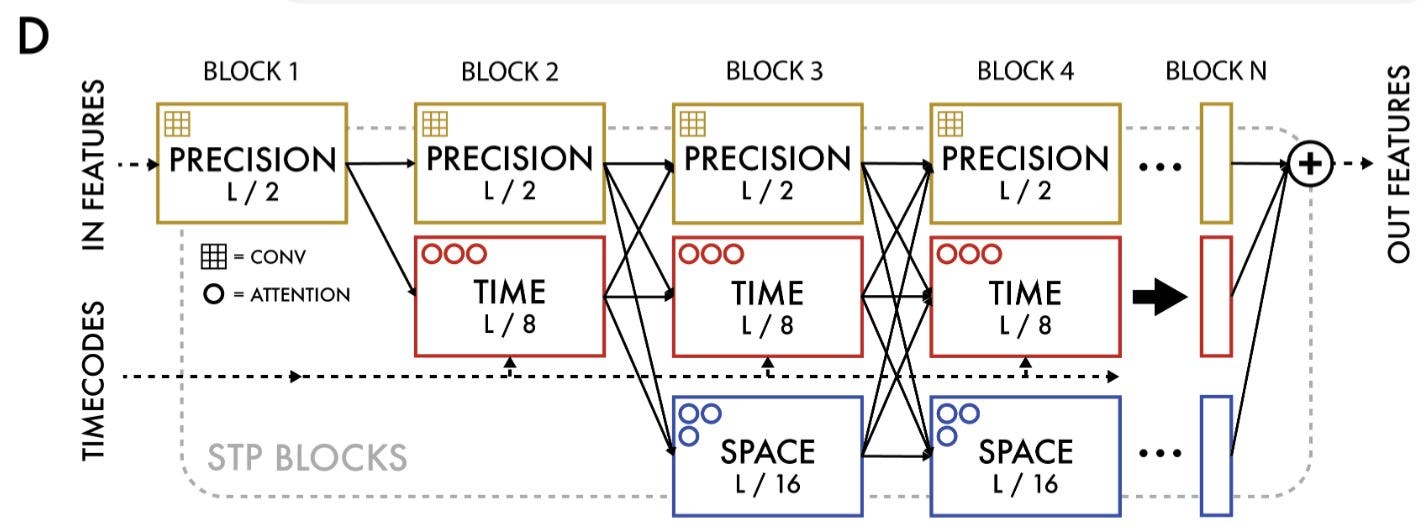
These operators run in repeated blocks, creating a rich, multi-scale representation of each location’s spatio-temporal context.
Self-Supervised objectives
How does AEF learn anything meaningful without millions of labels? Through self-supervised objectives:
Reconstruction. The model generates an embedding from an input video sequence, then reconstructs a held-out frame. This forces embeddings to encode enough information to recreate visual reality.
Teacher–Student consistency. Two models run in tandem. The teacher sees all frames; the student sees a degraded subset. If the student’s embedding diverges, the system is penalized.
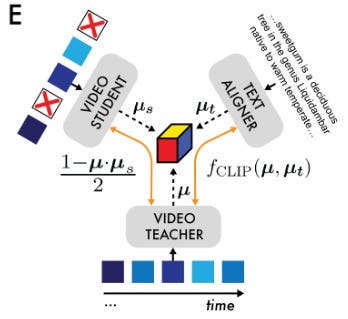
Text-contrastive alignment. Embeddings are aligned with text embeddings from a frozen Gemini model, pushing the system to group semantically similar places closer together (pine forest, wheat field).
Batch uniformity objective. Embeddings are constrained to distribute uniformly on the surface of a 63-dimensional sphere (S⁶³). This prevents collapse and maximizes the usable representational space.
The output primitive
The product of this entire process is compact but profound: a 64-dimensional vector (64 bytes) for every 10×10 m patch of Earth’s surface, annual from 2017 to 2024. Each vector is a dense semantic summary of that location across space, time, and modality.
Measured performance and engineering wins
An ambitious architecture is only valuable if it produces tangible results. Here’s the evaluation suite: fifteen tasks spanning land cover, crop type, tree genera, oil palm plantations, emissivity, and evapotranspiration.
Dominant and consistent performance. AEF outperforms every baseline: both traditional featurizations (like CCDC harmonics) and learned models (SatCLIP, Prithvi). On average, it reduces error magnitude by ~23.9% compared to the next-best model. This consistency is the core result: a single feature space works across domains.
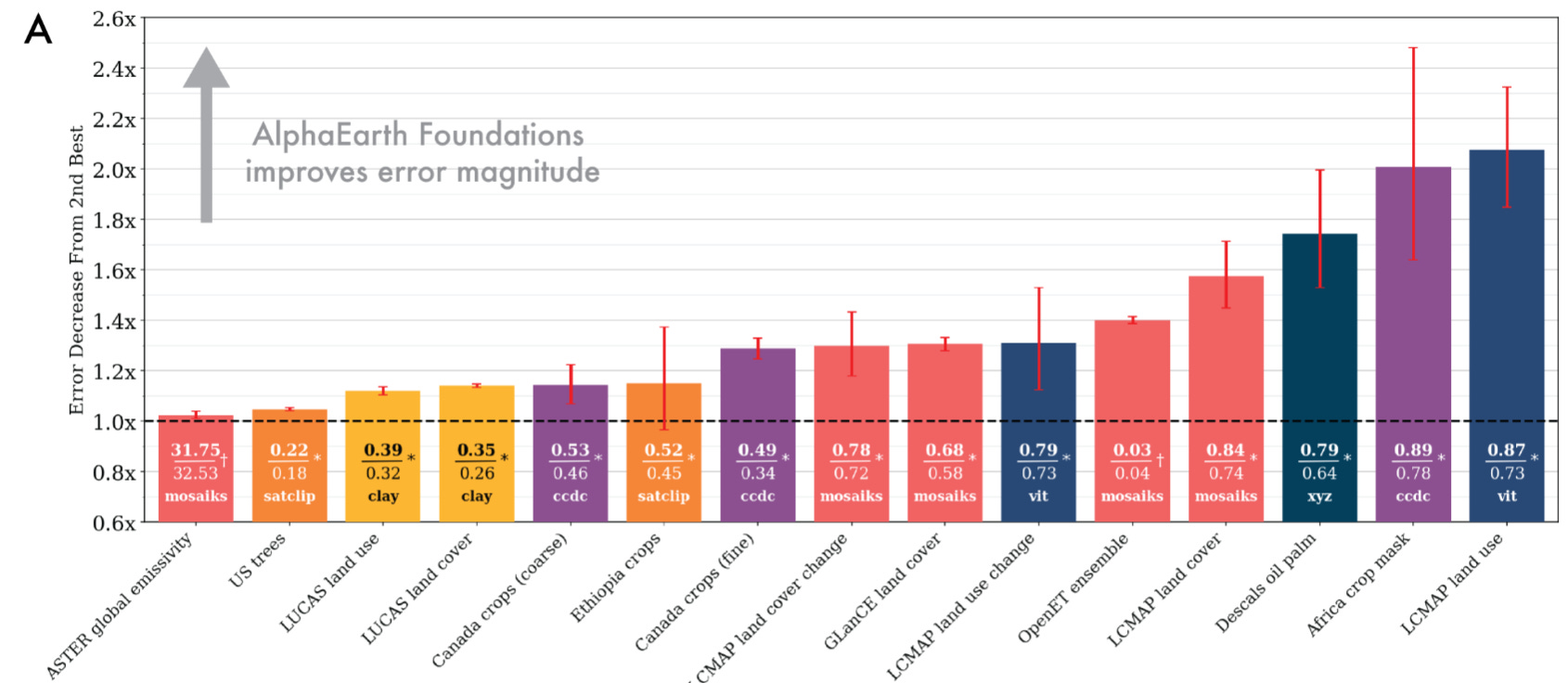
Storage efficiency. Each embedding is only 64 bytes. That’s 16× smaller than the next most compact learned representation.
Low-Shot learning prowess. In regimes with only a handful of labels, AEF still generalizes. With ten labels per class, it achieves ~10% error reduction; with only one label, ~4%. This makes it applicable in precisely the real-world settings where labels are scarce and expensive.
The takeaway is not that AEF is “a little better” than prior models. It is that it has turned the corner from domain-specific featurization to general-purpose representation.
What this enables in practice
Numbers alone don’t capture the shift. The real question is: what does having a universal planetary embedding make possible?
Similarity search. Start from a single location: a wheat field in Punjab, a mangrove forest in Indonesia — and immediately surface all other places on Earth with similar environmental and surface characteristics. What once required custom indices and local expertise becomes a straightforward query in embedding space.
Change detection. By comparing embeddings of the same pixel across years, it becomes trivial to detect and quantify change. Urban expansion, wildfire scars and regrowth, shifting reservoir water levels — all of these become visible as movements in latent space.
Automatic clustering. Without any labels, embeddings can be grouped to reveal hidden structure: differentiating forest types, soil compositions, or stages of urban development. This kind of unsupervised segmentation opens the door to discoveries that would be hard to design for explicitly.
Smarter classification. Where traditional mapping might require tens of thousands of labels, AEF makes it possible to train accurate classifiers with only hundreds. The embedding space already carries the relevant semantics; labels simply fine-tune the boundaries.
Limits and trade-offs
Every foundational system has edges. For AEF, they are clear:
Annual cadence. The public embeddings summarize one year at a time. Many ecological and agricultural processes demand sub-seasonal granularity. While the architecture supports continuous time, the release does not.
Geographic bias. Training samples cover ~1.1% of Earth’s land. Broad gradients are captured, but rare ecosystems and microcontexts are underrepresented.
Opacity. Embeddings are effective but not interpretable. For high-stakes use, interpretability tools must supplement them.
It’s just the price of compressing a planet into a universal feature space.
Conclusion
AlphaEarth Foundations is best understood as a starting point. What DeepMind has released is a compact, reusable layer of features that can make geospatial work faster and more consistent. Instead of spending time engineering custom pipelines, we can now start with a shared embedding of the planet and build small, task-specific models on top.
The embeddings are annual, they’re not fully interpretable, and they still need careful validation before being used in practice. But they lower the barrier to entry for a wide range of applications, from environmental monitoring to agriculture to urban planning.
In that sense, AEF gives experts a stronger foundation to work from. It shifts the challenge from building features to asking the right questions of the features we already have.

Sources
[1] AlphaEarth Foundations helps map our planet in unprecedented detail